|
|
Case for Support: PASOA
Provenance Aware Service Oriented Architectures
Luc Moreau, Omer F. Rana, and David Walker
Part 2: Proposed Research and its Context
The aim of this project is to investigate the underlying mechanisms
necessary to support a notion of provenance in Grid and Web Services
environments, and its use for reasoning about the quality and accuracy
of data and services.
As Grid and e-Commerce systems evolve into dynamic and open environments, offering
`community services' owned and managed by different providers organised in virtual
organisations [2],
the problems of determining the origin of a result, or deciding when results
of computation, such as a scientific analysis or a business transaction, are
no
longer valid become important concerns. Against this background, provenance data
is an annotation able to explain how a particular result has been derived; such
provenance data can be used to better identify the process that was used to reach
a particular conclusion.
This project addresses the overall aim of the ``Research in the Fundamental Computer
Science for e-Science'' call by identifying the nature of provenance, by defining
the means of generating it, and by offering reasoning mechanisms based on provenance.
In particular, our objectives are related to two of the research topics identified
in the call for proposals, namely: trusted ubiquitous systems, and traceability
of knowledge by relying on a provenance mechanism. Our proposal addresses some
of the cross-cutting themes:
- coping with evolution and change when trust must be maintained,
- frameworks to compose e-Science services in a principled way to promote
trust,
- new forms of shared scientific record.
We propose to tackle this research agenda, in partnership with the e-Science
projects the investigators are involved in, and in partnership with the industry,
specifically IBM (see support letter), also heavily involved in the e-Science
program and in
e-Commerce.
The proposed project has a duration of three years and will employ a post-doctoral
research assistant and a PhD student at Southampton and
Cardiff for that duration.
A. Background
Summary
Service composition and orchestration have been identified as key objectives
in the Grid and Web Services communities
[1, 4, 5, 3].
Workflow engines provide an important way to compose applications by connecting
services together, and a great deal of interest has emerged within the Grid community
related to this area [3]. In particular,
workflow engines allow users to identify, choose and compose services based on
their own particular interests. Understanding how a given service is likely to
modify data flowing into it, and how this data has been generated, is crucial
to allow a user to place their trust in that data. Such a concern can be illustrated
by the following generic question:
Let us consider a set of services deciding to form a virtual
organisation with the aim to produce a given result; how can we determine
the process that generated the result, especially after the virtual organisation
has been disbanded?
Provenance is therefore important to enable a scientist to trace how
a particular result has been arrived at. Provenance is also closely related to
the way in which data is archived, as knowing the process that led to a particular
result may help a scientist explore results that have been produced in a related
way. In this project, provenance is investigated from two particular perspectives,
described
below.
Execution Provenance relates to data recorded by a workflow engine during
a workflow execution. It identifies what data is passed between services, what
services are available, and how results are eventually generated for particular
sets of input values, etc. Using execution provenance, a scientist can trace
the ``process" that led to the aggregation of services producing a particular
output.
Service Provenance relates to data associated with a particular service,
recorded by the service itself (or its provider). Such data may relate to the
accuracy of results a service produces, the number of times a given service has
been invoked, or the types of other services that have made use of it. A service
provider may make such parameters available to other users to enable them to
select services that are more likely to produce the output they desire.
Producing provenance data is of no use if we do not provide the means of exploiting
it.
With our experience in the myGrid project, we have identified [10]
some uses of provenance data, e.g. determining if the result of an experiment
is still valid, determining if some tools used by an experiment have changed.
Generally, in this proposal, we will define reasoning on provenance
data as the computational process operating on provenance data which aims
to provide provenance-related information to the user.
A service user may also record data about the usage of a particular service.
This data represents a users' view of a particular service, and could include
attributes such as the number of times a particular service has been invoked,
the accuracy of results provided by the other service, etc. The types of data
that a particular user may record is based on the parameters used to encode Service
Provenance.
UK projects such as myGrid and combichem have provenance and e-labbooks high
on
their agenda; the recent workshop on provenance [9] also highlights
the interest by the Grid community. However, a number of fundamental research
issues still remain, such as:
- Guessing what provenance data should be, will result in an ad hoc solution.
In the spirit of the call for proposals, we firmly believe that the principled
design of such provenance data, and the understanding of its role in reasoning
are crucial to deliver a provenance model that is relevant to workflow
enactment.
- Provenance data generation is a cooperative process that requires the agreement
of multiple parties involved in workflow enactment; such parties need to
adhere to a common protocol.
- The specific properties of such a protocol will determine the quality of
the provenance data generated, and therefore the level of trust that scientists
can have in such data.
- Finally, the engineering of a provenance architecture suitable for a Grid
context needs to be addressed, and must take into account the dynamic and
open nature of such an environment, but also some of the domain performance
requirements.
Specifically, the objectives of the project are:
- To define execution and service provenance in relation to workflow enactment.
- To conceive algorithms to reason over provenance data, in order to help
scientists to achieve better utilisation of Grid resources for their specific
tasks.
- To design a distributed cooperation protocol to generate provenance data
in workflow enactment.
- To investigate value-added properties that can be deduced from provenance-based
data.
- To engineer a proof of concept software architecture to support provenance
generation and reasoning in Grid environments.
Detail
We distinguish execution
provenance from service provenance. Execution provenance is used
to identify the process that created a particular piece of data. It provides
a history of how the data originated, and any subsequent processing that took
place on it -- almost like an ``audit-trail'' that may be used to analyse the
transformation of data. Using such an execution provenance, one can decide if
a result is still up to date, or identify what part of a workflow needs to be
re-enacted, once some data has been updated or once a new service or a service
upgrade comes on line.
Service provenance relates to data that a service records about its own usage
(by other services), and the output types of data that was generated as a result
of a request. Service provenance therefore provides a historical record of how
a particular service was invoked, and the response type that was sent out as
a consequence. Service provenance may allow a service provider to improve the
way in which a service may be offered -- perhaps by looking for patterns of usage
of a given service. Alternatively, service provenance information may be used
by a service user to select between multiple possible services -- based on which
other service has acted as a client to
it.
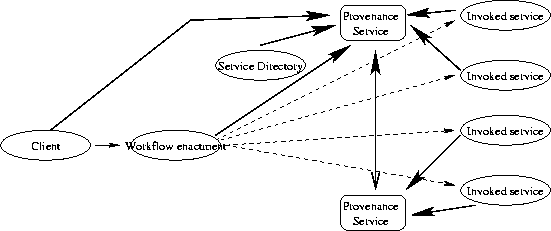
While the proposed project is to design the algorithms required for provenance
generation and reasoning, we sketch in Figure 1 some of its elements. First,
provenance gathering is a collaborative process that involves multiple entities,
including the enactment engine, the enactment engine's client, the service directory,
and the invoked services. Provenance data will be submitted to one or more ``provenance
repositories'' acting as storage for provenance data. Upon user's requests, some
reasoning over provenance data can be undertaken. We foresee here that storage
and reasoning could be achieved by a provenance
service.
Coordination is needed between the different entities involved in workflow enactment,
so that both execution and service provenance data is stored in suitable repositories.
In order for provenance data to be useful, we expect such a protocol to support
some ``classical'' properties of
distributed algorithms. For instance, using mutual authentication, an
invoked service can ensure that it submits data to a specific provenance server,
and vice-versa, a provenance server can ensure that it receives data from a given
service. With non-repudiation, we can retain evidence of the fact that
a service has committed to executing a particular invocation and has produced
a given result. We anticipate that cryptographic techniques will be useful to
ensure such properties. Such techniques are usually regarded as rather expensive,
and we may not like the process of provenance generation to hinder the progress
of workflow execution. In some cases, it may be useful to generate provenance
data in a manner that is asynchronous to workflow execution. Additionally, it
may not be realistic for all parties to submit provenance data to a single store,
but multiple provenance stores may be desirable to store provenance data, on
a temporary or long term basis.
In the bioinformatics community, it is common practice to consider manual (or
curated) annotations as part of the provenance data. In this project, we are
looking at automatic ways of gathering provenance information; this is compatible
with two ideas prevalent in the Grid community: service-oriented architectures
and workflow-based composition of services. Manual annotations can be fitted
into this view, provided that the process of capturing such manual annotations
is available as a service cooperating to generate provenance data, and it is
invoked during workflow enactment.
B. Programme and Methodology
The five key objectives of the project were enumerated in Part A of the proposal.
The proposed major
outcomes of the project will be the following.
- New algorithms and method to generate and reason over both execution and
service provenance data.
- An ontology and encoding format for supporting provenance in workflow enactment
engines.
- A Java-based proof of concept provenance-support architecture implementation
(i.e. libraries and services), allowing users to specify provenance attributes
in their particular domain.
- An integration of the prototype with e-Science projects the investigators
are involved with, namely GridOneD, GriPhyN, and myGrid.
Due to the variety of expertise required and the timeliness of the work, we seek
to employ two post-doctoral research assistants and two PhD students for the
three year period of the project.
Our proposed program is split into 6 workpackages; each of them is divided into
tasks, and we indicate which partner is undertaking the work (S for Southampton
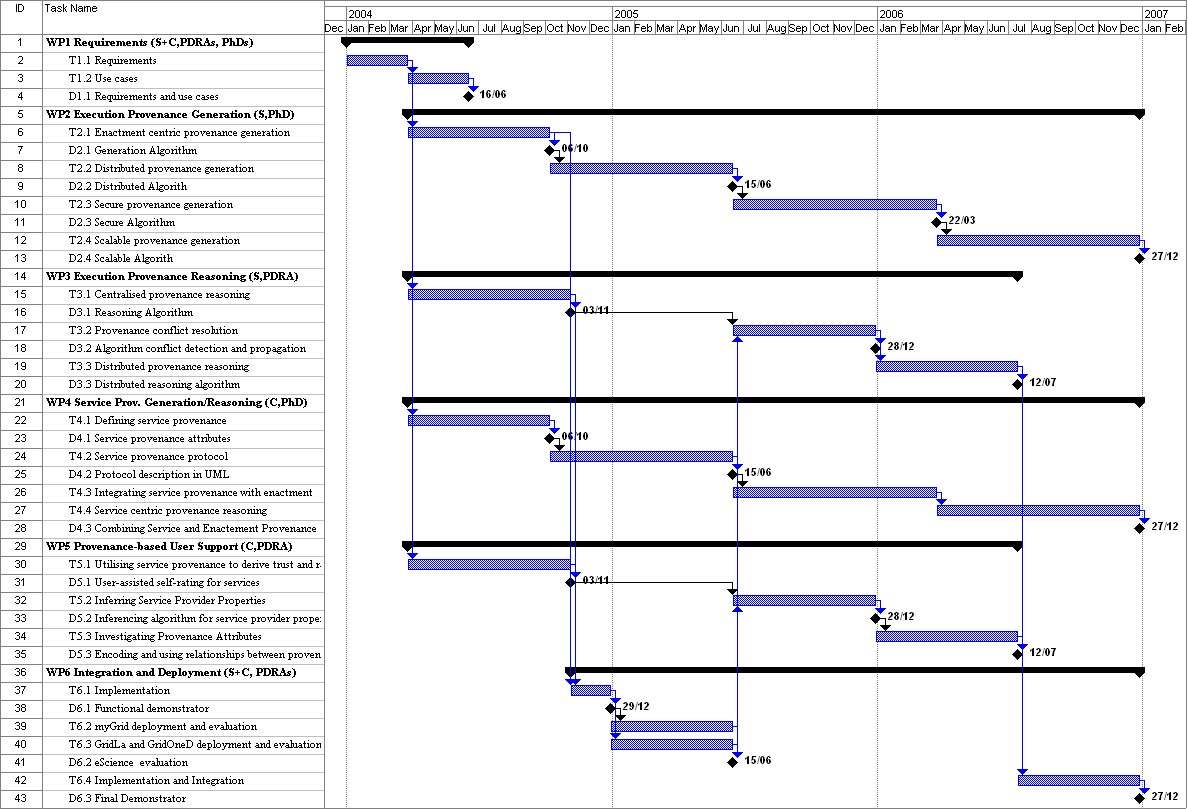
and C for Cardiff). Deliverables are also defined for each workpackage. The Gantt
chart in appendix provides all details regarding the timing of the
workplan.
WP1: Requirements (S+C)
The purpose of this workpackage is to identify the requirements of a system for
generating and reasoning on provenance data, as well as specifying a set of use
cases.
- T1.1
- Requirements
The purpose of this task is to define the requirements of a provenance
system. Both sites will participate in this activity, and will use their
experience in e-Science projects to define e-Science specific requirements.
In addition, in collaboration with IBM (as the industrial partner), we
will also investigate e-Business requirements.
- T1.2
- Use cases (3 M)
In this task, we will write up a series of use cases, for e-Science, eBusiness
and industrial systems. Some of these use cases will be derived from our
existing e-Science projects. Others will be obtained from discussion with
IBM.
Deliverable:
| D1.1 |
Requirement and use cases (report) |
WP2: Execution Provenance Generation (S)
This workpackage investigates the process of execution provenance generation,
and will initially focus on how such provenance should be generated by the workflow
enactment. This will result in a prototype (D6.1) that will be used in the deployment.
Subsequently, we will focus on the longer term issues, such as making the generation
process distributed, secure
and scalable.
- T2.1
- Enactment centric provenance generation
As our research proposal focuses on provenance data in the context of workflow
enactment, it is necessary to specify how provenance data can be generated
by a workflow enactor. Consequently, we will provide a semantics of workflow
execution which specifies:
- how services are invoked;
- what data is passed to or received from services;
- the process of provenance data submission.
The outcome of this semantics is a formal link between provenance data
and workflow execution.
During preliminary investigations, we have defined the semantics of uniprocessor
workflow enactment: we plan to extend such a semantics with parallel execution
of a complete workflow language; our work would draw upon our experience
on the semantics of parallel programming languages and of distributed algorithms
[8],
where we used a notion of an abstract machine to describe a system's
operational behaviour.
- T2.2
- Distributed protocol
In T2.1, we have assumed that the enactor was the only component in the
system to generate provenance data. In practice, all parties involved in
a workflow enactment should submit provenance data. There is some coordination
required so that, e.g., all parties correctly identify the workflow session
for which they are recording provenance data and the ``provenance stores''
involved in that process. This task will design such a protocol.
- T2.3
- Secure provenance generation
As Grid environments are typically open, we need to take measures to ensure
the veracity of provenance data. We anticipate that properties such as mutual
authentication and non-repudiation are required; we expect
this task to identify the required properties, and with the help of cryptographic
techniques (in particular digital signatures) we will extend the protocol
of T2.2 to ensure these properties.
At this stage, it is important to ensure the correctness of the protocol.
To this end, for the non-trivial task of deriving formal properties of
protocols, we will make use of a verification tool, such as Casper [6],
capable of converting a high-level description of a security protocol to
a CSP specification of the model that can be fed as input into the FDR
model checker [7] for subsequent
verification. We will draw on our experience of proving properties of cryptographic
protocols for mobile agents [13]
in order to mechanically prove the correctness of the cryptographic protocol.
- T2.4
- Scalable provenance generation
Provenance generation may result in high volumes of provenance data to
be submitted to provenance services. This process may be expensive, and
we would not want it to delay the execution of workflows. Therefore, it
may be desirable to submit provenance data in an asynchronous manner, essentially
``staging'' provenance data to temporary stores, and transferring it when
suitable. The purpose of this task is to define such a protocol to ensure
the scalability of the process of provenance generation. We also expect
this protocol to be secure.
Deliverables:
| D2.1 |
Centralised Generation Algorithm (report) |
| D2.2 |
Distributed Generation Algorithm (report) |
| D2.3 |
Secure Generation Algorithm (report) |
| D2.4 |
Scalable Generation Algorithm (report) |
WP3: Reasoning with Execution Provenance (S)
The purpose of this workpackage is to investigate the kind of reasoning that
can be performed on execution provenance data, the type of conclusions that can
be reached by such reasoning, and the information that execution provenance data
should contain to support such a
reasoning.
- T3.1
- Enactment-centric provenance reasoning (4 M)
Having formally defined how provenance data can be generated by the enactor
(T2.1), we can now examine the kind of reasoning that can be achieved on
provenance data. Requirements and use cases will identify examples of reasoning,
but we can already foresee some useful simple reasoning: e.g. checking
that a result is still up-to-date given a set of provenance data, or identifying
the point at which workflow would need to be re-enacted due to a change
in the environment.
T3.1 will focus on the reasoning that can be achieved for provenance data
provided by uniprocessor workflow execution, whereas the following tasks
will focus on the distributed setting. The different kinds of reasoning
will be specified in the same formal framework developed for the semantics
of T2.1, and will become the algorithmic foundations for the prototype
implementation.
- T3.2
- Provenance conflict detection
When multiple services cooperate to provide provenance data, new reasoning
can be undertaken due to the distributed nature of the process that produced
the provenance data. For instance, verifying the consistency of data through
a reconciliation process [13]
will ensure that a service A claiming that B was invoked
with some data is matched by a similar claim by B. This aspect of
the work impinges on ideas such as non-repudiation and service authentication
also.
An outcome of this task is to specify the means by which the provenance
infrastructure can notify the user (or the enactment engine working on
their behalf) about conflicts in provenance data. In this project, we will
not look at the means to solve such conflicts, but we will only seek to
detect them and notify them to the user.
- T3.3
- Distributed provenance reasoning
Finally, for scalability reasons, provenance data may be staged in temporary
repositories. As a result, the algorithms to reason over provenance data
have to be able to deal with data distributed at different locations.
Deliverables:
| D3.1 |
Reasoning Algorithm (report) |
| D3.2 |
Algorithm for conflict detection (report) |
| D3.3 |
Distributed reasoning algorithm (report) |
WP4: Service Provenance Generation and Reasoning (C)
This WP will focus on recording provenance data about a particular service, and
associating this with a service interface. The types of data that a service provider
may wish to record about a particular service may vary, and is based on the context
in which a particular service is being deployed. For instance, a service provider
may wish to remain anonymous. Hence, provenance attributes that are relevant
for existing e-Science applications will be identified, and the focus will be
on those that can be easily deployed within the existing infrastructure (such
as using ontology
languages like OWL [OWL:2002]).
- T4.1
- Defining service provenance
This task will focus on identifying provenance attributes that must be
recorded by a service. The aim is to allow each service to record its own
usage, and enable this recorded data to be subsequently queried by other
services. Provenance data will be associated with two main aspects of a
service: (i) output types and values being generated by the service, (ii)
access patterns and performance measures associated with a service. This
task will identify which of these attributes can be monitored/measured
using existing Grid middleware, and which can be derived based on measured
data.
- T4.2
- Service provenance protocol
The service provenance protocol will explore how interactions outlined
in T4.1 may be supported -- identifying the types of message exchanges
and the contents/encoding of these messages. The task will also explore
how data about a service may be encoded, and ways in which it may be associated
with a service interface. The use of provenance servers/repositories to
record this data will be investigated. The protocol will be simulated using
the GreatSPN Petri Net tool.
- T4.3
- Integrating service provenance with enactment
This task will focus on extending the protocol in T4.2 to interact with
the enactment engine (T2.1 and T2.2).
- T4.4
- Service-centric provenance reasoning
Once service provenance data has been generated, this task will explore
the types of reasoning that can be undertaking using this data. Reasoning
can include aspects such as the number and types of service requests to
a given service.
Deliverables:
| D4.1 |
Service Provenance Attributes (report) |
| D4.2 |
Protocol description in UML, and simulation using
GreatSPN Petri Net tool (report and simulation) |
| D4.3 |
Combining Service and Enactment Provenance (report) |
WP5: Provenance-based User Support (C)
The aim of this WP is to utilise service provenance data to derive additional
Provenance attributes. Such attributes relate to aspects such as reliability
or fault
tolerance, that cannot be directly measured/monitored.
- T5.1
- Utilising service provenance to derive self-rating attributes and trust
Allowing a service to record parameters associated with its execution,
and enabling other services to query these, is only useful if undertaken
subject to privacy constraints. This task will explore how trust relationships
may be established between a service provider and user, and how these may
be used to support service selection. Whereas the focus of task T4.1
is on provenance data recorded by a service (provider), the focus here
will be to investigate how a client (user) could rate a given service based
on previous usage. This rating will in turn be influenced by the types
of parameters that can be obtained from a service provider.
- T5.2
- Inferring service provider properties
Inferring common properties across a set of services is useful to identify
particular trends of use. This task will investigate the development of
an analysis algorithm over the recorded properties for a service collection.
This task extends work in T4.4 by exploring common properties (such as
request patterns) that may arise across a group of services.
- T5.3
- Investigating provenance attributes
This task will investigate how provenance attributes associated with a
service relate to each other -- based on data recorded about these attributes.
Some relationships between attributes will be automatically available in
the encoding of service provenance (T4.1), whereas others must be derived
from service usage and requests. This task will explore how such relationships
arise, and how they could be made available to a workflow engine.
Deliverables:
| D5.1 |
User-assisted self-rating for Services (report) |
| D5.2 |
Inferencing algorithm for Service Provider Properties
(report and software) |
| D5.3 |
Encoding and Using Relationships between Provenance
Attributes (software) |
WP6: Integration and Deployment (S+C)
While workpackages WP2 to WP5 deliverables identify what provenance data is,
how it has to be generated, and what it can be used for, this workpackage will
focus on the practical implementation and integration, and the deployment of
a provenance system in a Grid environment. The industrial partner IBM will also
be involved
in the deployment and evaluation phase.
- T6.1
- Implementation
The purpose of this task is to build a functional demonstrator, capable
of generating provenance data by the enactor, and offering some centralised
reasoning capability, as specified in D2.1, D3.1, D4.1 and D.51.
- T6.2
- myGrid deployment and evaluation
We will deploy the functional demonstrator into the myGrid infrastructure.
The deployment will require integration at two levels. The myGrid workflow
enactment engine will have to submit provenance data to our provenance
service according to the format and protocol that we have specified. The
myGrid user interface will be extended so that the provenance data generation
and reasoning capabilities are exhibited to the user.
- T6.3
- GridLab and GridOneD deployment and evaluation
Both the GridLab (European Union/IST Programme) and GridOneD projects utilise
a workflow engine. Each service within this engine has an XML-based interface,
which may be extended with service and enactment provenance attributes.
User support, outlined in WP5, will then be implemented over this data
model.
As far as timing is concerned, we have planned the integration with existing
e-Science projects at an early stage, so that they can give us practical
feedback to be used in the rest of the project. We will use the myGrid,
GridLab and GridOneD deployments, and the feedback from IBM, to evaluate
the capabilities provided by the functional demonstrator.
- T6.4
- Implementation and integration
We will implement and integrate into the demonstrator the algorithms for
distributed, scalable and secure provenance generation and reasoning. Support
will also be provided for encoding provenance properties of individual
services, and how these may be used to influence workflow enactment.
Deliverables:
| D6.1 |
Functional Demonstrator (software) |
| D6.2 |
e-Science provenance evaluation (report) |
| D6.3 |
Final Demonstrator (software) |
The diagrammatic project plan appears in part 3 of the proposal. A post-doctoral
research assistant and a PhD student will be employed by each site. The workpackages
have been allocated to the different sites, according to their expertise: workpackages
2 and 3 will be undertaken by Southampton, 4 and 5 by Cardiff, and 1 and 6 will
be shared by both sites. We will use workpackage 6 to synchronise the activities
between sites: at the same time, both sites will undertake practical designs,
implement services and libraries, integrate their code and deploy it in e-Science
projects
in tasks T6.1 to T6.4.
The use of PhD students is appropriate for workpackages 2 and 4 as they are well
defined and delimited activities, which can mostly be performed in an autonomic
manner so as to ensure the required level of originality for a PhD; their results
will be exploited and integrated as soon as available. The proposed titles for
the PhD will be ``Secure and
Scalable Execution Provenance Generation'' (WP2, Soton) and
``Service-Provenance Generation and Protocol to Support Grid
Infrastructure'' (WP4, Cardiff).
The investigators will be closely involved with technical issues throughout the
project, and will meet weekly with the researchers. We anticipate use of the
AccessGrid for such meetings (as already employed for preparing this proposal).
There will be quarterly management meetings with investigators, where strategic
issues are
addressed.
C. Relevance to Beneficiaries
Workflow has been seen as a significant activity within many e-Science/Grid projects
currently underway. However, the emphasis within many of these projects remains
on service composition, and not provenance. The objectives of this project related
to execution and service provenance, outlined in section A, therefore complement
existing activities well, and may be usefully deployed as a service within existing
systems.
Associating provenance information with Grid services and systems remains an
important concern -- as deciding which data to record about the entire workflow
process, and about each each service, is a non-trivial undertaking. In this project,
we address this issue directly as part of WP2 and WP4, to elucidate better the
types of data that are likely to be useful in the context of existing e-Science
application testbeds (such as GridOneD, myGrid,
GridLab).
The project's outputs will be made available to the e-Science activities the
investigators are involved with, and integrated in their software architectures.
Symmetrically, we also expect these activities to inform our
design.
While myGrid is also preoccupied with provenance, the prevailing thinking is
currently about provenance generation that is not regarded as cooperative, and
not related to both execution and service. Additionally, a myGrid ontology is
being designed, but it is not coming with the principled design that we advocate
in this proposal, where provenance data should be specified in relation with
workflow enactment and with its associated reasoning (WP1). Finally, studying
the properties of a distributed protocol is beyond the scope of result driven
pilot projects. Combichem is concerned with the notion of an electronic labbook,
but does not study how provenance data can be automatically gathered
from invoked services. Our research agenda is therefore a good complement to
both projects.
D. Dissemination and Exploitation
We expect the results of this work to be disseminated by publication at appropriate
national and international conferences and in international journals. We shall
maintain an
up-to-date online archive of technical reports and published papers.
The Global Grid Forum, the World Wide Web Consortium and the AgentCities task
force
(the follow-on ``OpenNet" is currently being submitted to the IST
Framework 6 call) are also ideal forums to present our results on provenance
services. One of the proposers co-chairs the ``Service Management Frameworks''
research group in the Global Grid Forum, and is an active member of the recently
formed ``Semantic Grid'' research group. The proposed work will be disseminated
to participants within these groups.
E. Justification of Resources
Personnel. Our programme asks for support for two full-time PostDoctoral
Research Assistant (PDRA) and two PhD students for a period of three years. As
we expect the PDRAs to be familiar with Grid systems, workflow enactment, and
Web technologies, with a good understanding of distributed systems, we have set
the staffing grade on this basis. There is a significant support requirement
in distributed systems projects such as this, hence we request a proportion (10%)
of a systems programmer. Secretarial staff (5%) will provide administrative support
to the
project.
Consumables. A project of this nature makes particular demands on server
and network infrastructures and we include a standard contribution to the support
cost. Our request for equipment support and associated consumables follows standard
laboratory and departmental practice. The associated office equipment and network
connections are included at costs prescribed by the department for this purpose.
We also include maintenance of a
server that we will make use of.
Travel. While both Southampton and Cardiff are AccessGrid nodes that
we plan to use actively, we seek funds for physical meetings with our collaborators,
in particular during the three integration phases. With our experience of the
e-Science programme, we also seek funds to attend relevant workshops organised
by the national e-Science center and the e-Science programme. We also seek funds
to attend relevant workshops and conferences, and would normally expect to submit
papers to these. This is an active research area, some events are well established
and new ones are emerging: we wish to attend them when they are essential to
the project. Examples of established conferences or meetings in this area are
SC, CCGrid,
HPDC, GGF and AAMAS.
Equipment. We seek funding for two laptops and PCs for each PDRA, and
a PC for each PhD student at Cardiff and Southampton. We expect to develop our
architecture on PCs and deploy our systems on servers available in Southampton
and Cardiff, and other e-Science collaborators. The iam lab
is a well-equipped laboratory including several multi-processor Sun Servers LAN,
ATM, a connection to the 6Bone, the world wide experimental network for IPv6,
and a wireless LAN. The department of computer science at Cardiff hosts the Welsh
e-Science centre, consisting of a multi-processor Sun E6500, an SGI Origin, and
a Linux cluster. The centre also hosts the Cardiff Distributed Visualisation
Facility, consisting of multiple Immersa-Desks (from Fake Space), and SGI based
visualisation workstations. Many of the projects undertaken on this equipment
at Cardiff involve
workflow.
References
- [1]
-
Ian Foster, Carl Kesselman, Jeffrey M. Nick, and Steven Tuecke.
The Physiology of the Grid --- An Open Grid Services Architecture
for Distributed Systems Integration.
Technical report, Argonne National Laboratory, 2002.
- [2]
-
Ian Foster, Carl Kesselman, and Steve Tuecke.
The Anatomy of the Grid. Enabling Scalable Virtual Organizations.
International Journal of Supercomputer Applications, 2001.
- [3]
-
Grid computing environments working group at the global grid forum.
http://www.computingportals.org/, November 2002.
- [4]
-
Madhusudhan Govindaraju, Sriram Krishnan, Kenneth Chiu, Aleksander Slominski,
Dennis Gannon, and Randall Bramley.
A Component Based Programming Model for Grid Web Services.
Technical Report 562, Indiana University, Bloomington, Indiana, June
2002.
- [5]
-
Frank Leyman.
Web Services Flow Language (WSFL).
Technical report, IBM, May 2001.
- [6]
-
Gavin Lowe.
Casper : A compiler for the analysis of security protocols.
In Proceedings of The 10th Computer Security Foundations
Workshop. IEEE Computer Society Press, 1997.
- [7]
-
F.S.E. Ltd.
Failures-Divergence Refinement : FDR2 User Manual, Available at
http://www.formal.demon.co.uk/fdr2manual/.
Technical report, Formal Systems Europe, 1999.
- [8]
-
Luc Moreau and Jean Duprat.
A Construction of Distributed Reference Counting.
Acta Informatica, 37:563--595, 2001.
- [9]
-
Web ontology language (OWL).
http://www.w3.org/TR/owl-ref/, November 2002.
- [10]
-
Data provenance/derivation workshop.
http://people.cs.uchicago.edu/ yongzh/position_papers.html, October
2002.
- [11]
-
Mygrid provenance page.
http://phoebus.cs.man.ac.uk/twiki/bin/ view/Mygrid/ProvenanceData,
2002.
- [12]
-
Hock Kim Tan and Luc Moreau.
Extending Execution Tracing for Mobile Code Security.
In Klaus Fischer and Dieter Hutter, editors, Second
International Workshop on Security of Mobile MultiAgent Systems
(SEMAS'2002), DFKI Research Report, RR-02-03, pages 51--59, Bologna, Italy,
June 2002. DFKI Saarbrucken.
Part 3: Diagrammatic Project Plan
Gantt chart
This document was translated from LATEX
by HEVEA.
|
|

{kind=link}